
There was a time when SQL databases were the de-facto choice when developing a new application. In recent years, NoSQL databases have become a popular alternative. Choosing between a SQL vs NoSQL database is now an important technological decision for app developers, and recognizing when to use one over the other is an important skill to have. Beyond that, the choice of which type of database to use can determine whether a project will run smoothly or experience technical difficulties as it grows.
In this article, we’ll explore the differentiating factors between the two database types and when one outperforms the other. We’ll see that a key factor in making a decision is being able to recognize the type of data that your application has to handle and then using that to determine which technology is best suited for your situation.
First, we’ll need to quickly explore the technical principles behind the two classes of databases so we can recognize what sets them apart to inform our future decisions.
What are SQL Databases
SQL databases are the older and more widely used of the two data storage systems. Examples of the most popular SQL databases include:
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Oracle
- MariaDB
SQL databases are classified as relational databases which follow the relational model proposed by E. F. Codd in 1970. The relational model introduced the idea of organizing data as tuples, also known as rows, that are grouped into relations, also known as tables.
SQL databases are best suited for storing structured data. Before starting to add data to a relational database, one must first define the database schema. Schema refers to the relationship between the database tables (relations) and the types of fields (columns) that these tables have. In other words, you first have to declare the structure and types of your data before you can begin storing and manipulating it. This makes SQL databases the stricter of the two, as it requires design foresight and can necessitate restructuring as a project evolves. Database administrators must also be careful when designing their schema in order to avoid data redundancy and optimization issues.
SQL databases implement the Structured Query Language (SQL) to work with data. SQL is typically more comprehensible than traditional code as it utilizes English keywords like SELECT, INSERT, UPDATE, DELETE along with boolean operators like AND and OR. SQL supports many powerful features for working with data, such as the JOIN clause, which a developer can use to perform complex queries and retrieve data from multiple tables as one result.
Aside from proprietary functionality, the core syntax of SQL is consistent between different database vendors, making it relatively easy for developers to transfer their knowledge from one system to another. For example, a developer with experience using MySQL will quickly be able to pick up PostgreSQL and vice versa.
What are NoSQL Databases
NoSQL databases are database systems that are not based on the relational model. Although such databases have existed since the late 1960s, the term NoSQL appeared in the early 2000s and has gained popularity since then. Some examples of common NoSQL databases include:
- MongoDB
- CouchDB
- Redis
- Elasticsearch
- Cassandra
The popularization of NoSQL systems began as the result of the need for scalability and flexibility, especially from tech giants handling large and diverse sets of data.
NoSQL databases are essentially a flexible storage engine. NoSQL databases are schemaless, meaning that they do not strictly define the tables and the relations between them. Being schemaless eliminates the need for the type of careful design required by relational databases and removes many restrictions surrounding data type and format. This allows for the insertion of diverse data regardless of the shape of existing entries.
NoSQL databases can be categorized based on the type of data model they use:
- Key-value: A simple lookup system similar to an associative array, map, or dictionary where a given key corresponds to a respective value. Example: Redis.
- Document: Used when the data being stored is a consistent “document” type such as JSON, XML, etc. Documents are accessed by unique key as well as by querying their contents. Example: MongoDB.
- Wide column: Uses tables, rows, and columns, but lacks schema restrictions. Example: Cassandra.
- Graph: When the data being stored is a mathematical graph. Example: Neo4j.
Due to the variance in NoSQL databases, the type and shape of the data being stored often determine which solution to use. When compared to SQL databases, transferring knowledge of one NoSQL system to another can be more difficult depending on how much the two systems differ.
Comparing SQL vs NoSQL Databases
Data integrity vs Availability
Most relational databases provide guarantees according to the ACID set of properties. In short, relational databases that conform to ACID provide the guarantee of data validity despite any unexpected errors. However, this comes with some cost in performance because data has to first get written to the disk before the client gets a successful response.
On the contrary, NoSQL databases rely on the eventual consistency model in order to achieve high availability. NoSQL databases do not wait for the data to be written on the disk before sending a response to the client as shown in the illustration below.
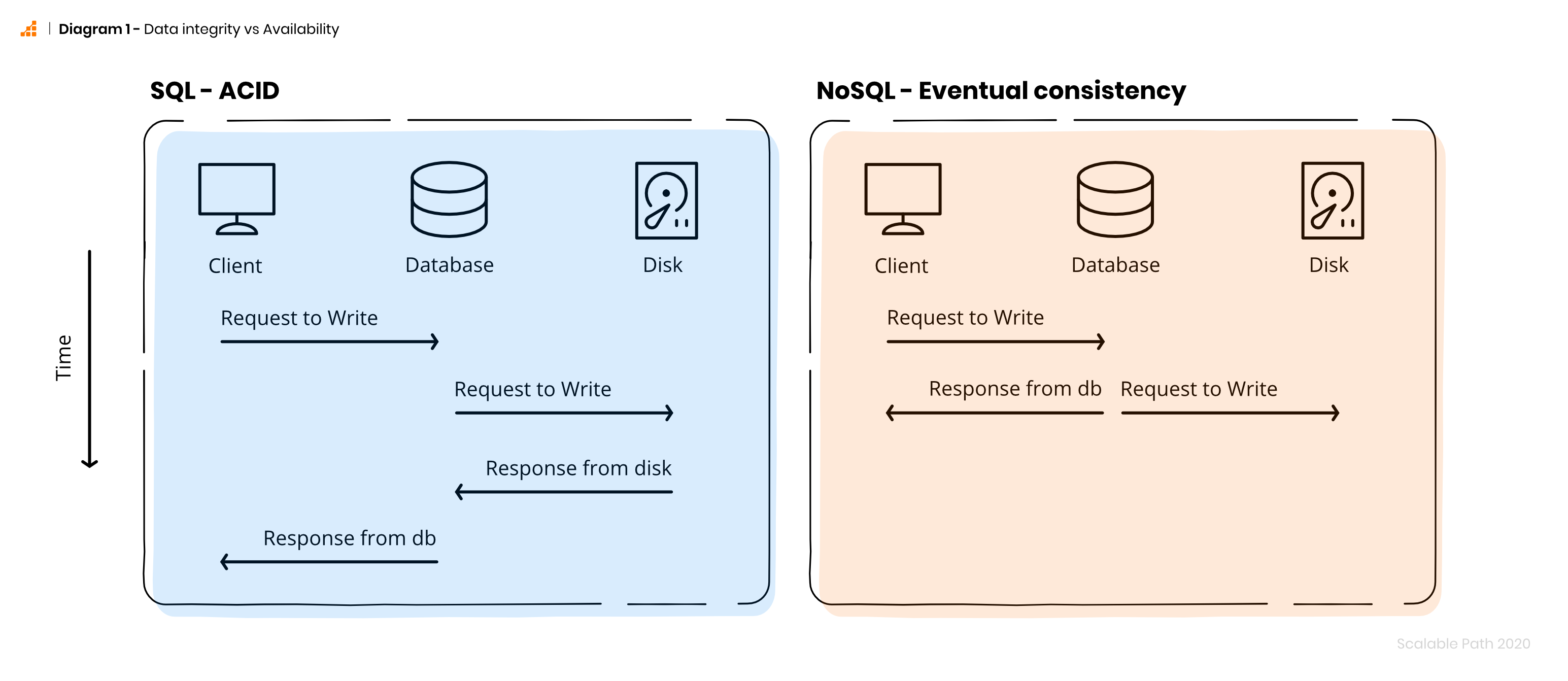
As a result, relational databases offer guarantees for data integrity but may respond slower than NoSQL databases which provide a high level of availability while sacrificing a level of reliability.
Schema vs Schema-less
Relational databases use their schema to describe the database and the types of data that it handles. On the other hand, NoSQL systems do not use a database schema, so it is quicker for someone to add data in a different form without having to make any additional changes to the database. There is a tradeoff here between ease of use for NoSQL databases versus the quality and consistency of data in SQL databases.
To JOIN or not to JOIN?
Relational databases store data in multiple tables trying to eliminate duplicate information. This is called normalization. For example, let’s say we want to store data about books and each book has a title and an author. In a relational database we would have a table called books that would have 3 fields (id, title, author_id) and another table called authors that would have 2 fields (id, name). So when you want to query the database and get all books that a specific author has written, you can use JOIN to combine information from both tables in one query, like so:
SELECT * FROM books
JOIN authors ON books.author_id = authors.id
WHERE authors.id = 1On the other hand, if we had to use a NoSQL database to store this kind of data, we would have to keep duplicated information in order to keep all books in a collection called books. Each book would be a JSON object like this:
{
id: 1,
title: 'Clean Code',
author: 'Robert C. Martin'
},
{
id: 2,
title: 'The Clean Coder',
author: 'Robert C. Martin'
},
...
We either have to keep duplicate information (the author’s name) and get all the books in one query, which is quite quick, or we have to create another collection to keep the authors and reference each author by his id inside each book record. The second case forces us to make a query to get the books and another query to get the authors and then combine the information manually to get the final result, not very efficient.
Vertical vs Horizontal scaling
Vertical scaling means that you scale by adding more power to a server whereas horizontal scaling means that you add more servers. NoSQL databases are designed to facilitate horizontal scaling by distributing data across multiple servers. Maintaining your data across multiple servers with a NoSQL database is relatively easy because there is no schema that has to be kept up to date. Adding more servers to a relational database is tricky because it is difficult to maintain the schema and safely keep the data consistent between instances.
Distributing data across multiple servers helps to avoid a single point of failure. A failure of a server that is part of a distributed system may not cause a total failure of the application. If a database is maintained in one machine, a failure of that machine means a failure of the system as a whole.
Examples of when to use SQL vs NoSQL Databases
When to use SQL Databases
SQL databases are suited for applications where the integrity of the data is important. If you have an application that handles critical data like financial information, you should use a relational database in order to be sure that any query you make will get you the correct response and that you will not accidentally lose any data. In this case, you want to have the maximum consistency, possibly by sacrificing a level of availability in comparison to NoSQL.
When your data is structured enough and can be relatively easily organized into schemas you can choose a SQL database because it is a natural fit for structured data. If the database schema is well designed you can reduce data redundancy through normalization by abstracting out duplicated information. This will also help improve the quality of your data.
When to use NoSQL Databases
If you develop an application that handles a large number of simultaneous requests from multiple clients and has to maintain a high level of availability, then you might want to use a NoSQL database. Such an application might be a live chat app or message queue that has to instantly respond to the client without latency. By using a NoSQL database you can be confident that you can achieve a low response time and in the worst case you might lose a message that has not been written to the database. If you can afford to sacrifice a level of data consistency in favor of high availability, you should definitely choose a NoSQL database.
When you have to deal with big data that is not so well structured you may also choose to use a NoSQL database. This will allow you to easily scale horizontally, in contrast to relational databases where this is not as easy. NoSQL databases offer you the choice to distribute your data across multiple servers, a fact that allows some NoSQL systems to easily recover from unexpected crashes by having no single point of failure.
When you want to perform complex and fast search queries on huge amounts of data, Elasticsearch is a NoSQL solution that fits that scenario. An example of such an application might be a text search app that needs to perform search queries to find a specific term through thousands or millions of documents.
Given their flexibility, NoSQL databases may also be useful when developing prototypes and MVPs. Time can be saved in not designing a schema, and analyzing the collected data can help guide the schema design process for the final product.
Don’t Let The Framework Determine the Database
Frequently, technology stacks and application frameworks have a “default” database that most people use simply because that’s “the way it’s done” in most tutorials (and the community as a whole). For example, in the LAMP stack (Linux, Apache MySQL, and PHP), people tend to use a SQL database and in the MEAN stack (MongoDB, Express, Angular, and Node.js) people tend to use a NoSQL database. JavaScript applications have an easy time sharing data with MongoDB because it stores data in JSON format, and many Node.js developers are accustomed to this. Still, NoSQL databases are not the right choice for every Node.js project. To make this important decision, it’s worth taking the time to investigate the best structure for your application data.
The Best of Both Worlds
Database vendors are constantly adding features in order to stay competitive. This can include SQL databases adopting traditionally NoSQL-type functionality and vice versa. On the SQL side, we’ve seen Postgres add robust support for storing and working with JSON types, while SQL Server has done the same for XML. Meanwhile, MongoDB has added the JOIN-like $lookup operator and OrientDB claims ACID compliance. It seems that the next step in evolution for SQL and NoSQL databases alike may be a blurring of the lines that makes them distinct from each other – all to the benefit of the developer.
Conclusion
Choosing the right database is an important technological decision when developing an app. An incorrect decision can lead to growing pains or even data loss once an app begins to take off. Although it’s possible to change technologies part-way through a project, you’ll save yourself the headache by making the right choice out of the gate.
The database you choose should be able to optimally handle the type of data that your application will store. If data integrity is key and your data is predictably structured, you should go with a SQL database. SQL also provides a powerful query language for working data which can be useful throughout a project. Conversely, if flexibility and scalability are more important to you, NoSQL may be the better option – and picking the right type of NoSQL database will also be important.
In my opinion, you should use a relational database unless it isn’t feasible given the nature of the data. If your application has to handle a large amount of denormalized data that is highly variable, then NoSQL may be required. What’s important is that you take the time to recognize the advantages and disadvantages of the two types of databases and then choose which is right for you.
Are you looking to hire a software developer?
You’ve come to the right place, every Scalable Path developer has been carefully handpicked by our technical talent team. Contact us and we’ll have your team up and running in no time.