
One of the most important things you can do when approaching a data science project is really understand the dataset you’re working with as a first step. Without a proper data exploration process in place, it becomes much more challenging to identify critical issues or successfully carry out a deeper analysis of the dataset.
What Is Exploratory Data Analysis?
Exploratory Data Analysis (EDA) in Data Science is a step in the analysis process that uses several techniques to visualize, analyze, and find patterns in the data. John Turkey, who developed the EDA method, likened it to detective work because you have to dig for clues and evidence before making any assumptions about the outcome.
A complete and solid EDA can help identify issues in your data like missing or wrong values, typos, and anomalies (outliers). In addition, you will learn about the distribution of the data, the relationship between variables, and find variables that may not affect the desired outcome. In this article, we’ll explore the principle techniques of Exploratory Data Analysis, tools, and graphs that help to understand the data better so you can ultimately answer business questions and find insights that may surprise your stakeholders.
Types of Variables in the Exploratory Data Analysis
When you start to explore the dataset, the first thing you have to evaluate is the attributes of the data you’re working on. Understanding the type of each variable will help you in the process of choosing the proper technique for the attribute analysis.
Types of Data: Quantitative vs. Qualitative
- Quantitative Data: These are numerical values and can either be discrete or continuous. Discrete means a finite number, like the number of children in a family, for example. Continuous, on the other hand, represents infinite numbers, like a person’s weight.
- Qualitative Data: These are categorical values, which divide into two subtypes: nominal and ordinal. Nominal data are categorical values with no order relation, like gender and color. Ordinal data means that an order exists within the categories, but the distances between them are unknown like a person’s level of education. It’s also worth noting that discrete data can sometimes be transformed into ordinal data, for example, grouping ages in ranges.
With this understanding of the basics, you can then perform Univariate Analysis.
How to Analyze Data Using Univariate Analysis
Univariate Analysis is the simplest form of data analysis. ‘Uni’ refers to analyzing one individual attribute to understand the position of the data in the dataset by the central tendency measures and the sparseness of that data by the dispersion measures.
What Are Central Tendency Measures?
The central tendency measures use the following:
- Mode: The most frequent value in that attribute. It’s possible to have no mode (flattened distribution), one mode (unimodal distribution), or more than one mode (multimodal distribution). Also, this measure can be used either by qualitative or quantitative data, but qualitative data uses it more often.
- Median: The central value of the ascending ordered data. This measure is used by quantitative data and is very resistant to outliers.
- Mean: The most known and used measure. It represents the sum of all values divided by the total number of values. This type of measure is used by quantitative data, and it’s very sensitive to outliers.
- Quantile: Divides ordered data in nearly equal sizes. The quantile 50% represents the median, and one of the most common quantiles is called quartile, which splits the data into four parts of 25% each. However, the position measurements are not sufficient to characterize the distribution of data, and therefore we need to analyze dispersion measures.
What are Dispersion Measures?
Before jumping to the dispersion measures, let’s look at an example of why it’s worth doing. Imagine that we have a set of employee salary ranges with the following values:
[3200, 3900, 3400, 3500]
The mean of this dataset is 3500. But, you can achieve the same mean with a set of different values. For example:
[500, 3500, 3000, 7000]
Again, the mean is 3500 even though the data is more concentrated in the first example and more sparse in the second example. This is what the dispersion measures will show us. Let’s explore this further to understand what it is and how it works.
The dispersion measures show the variability of the data set, and when analyzed together with the position measures, it gives a big picture of how the data is distributed. To understand the sparseness of the data, we will look at the following measures: variance, standard deviation, amplitude, interquartile range, and coefficient of variation.
- Variance: This indicates how far the values are from the expected value.
- Standard deviation: This is the square root of the variance and expresses the degree of dispersion of the dataset. When you have a low standard deviation, the values tend to be close to the expected value, but those values are spread over a wider range when it’s high. The standard deviation value can be read in the same scale of the original observation, while the variation is in the squared scale.
- The amplitude (range): This is the difference between the largest and smallest value in the data, and it’s useful only to give a rough idea of the range that the observations fall. This measure is sensitive to outliers and doesn’t provide much information because it doesn’t use all the values.
- Interquartile range: A more robust measure is the interquartile range (IQR), which is the difference between the third quartile and the first quartile. It’s also not sensitive to outliers because the extreme values are ignored. The outcome of this measure describes the middle 50% of observations of the dataset. The larger this value is, the more spread out the data.
- Coefficient of variation: The last measure of dispersion to introduce is the coefficient of variation and is also called the relative standard deviation. This measure is the ratio of the standard deviation to the mean and represents how much the observations vary in relation to the mean. It’s a valuable measure when we want to compare two attributes on a different scale because it expresses the variability of the data, excluding the influence of the order of the variable’s magnitude.
With the understanding of these measures, you can analyze the attributes individually and get some insights. Next, let’s learn how to do an analysis using more than one variable.
How to Apply Multivariate Analysis
After analyzing the attributes individually, the next step is to understand the relationship between them. With this analysis, you can get some relevant insights, verify the degree of correlation of those variables, and bring valuable information for the project’s subsequent phases. Let’s take a look at some of the correlation coefficients. The correlation coefficient is any statistical relationship (causal or non-causal) between two variables. The values can go from -1 to 1, and the value in the extreme means that we have a high correlation between both variables. When the value is positive, both variables go in the same direction, and when it is negative, one increases, and the other decreases.
What Is Pearson Correlation?
Pearson Correlation is one of the most common measures and analyzes how the variables are linearly related. This measure is very sensitive to outliers and is used only for quantitative data (which is why it’s essential to understand the type of each variable at the beginning of the analysis). Depending on the type of data, you will need to use different techniques. Suppose you analyze two quantitative variables from your dataset, and the result of the Pearson Correlation is around 0 (which means that there is no linear correlation). In that case, it doesn’t mean that those variables are not correlated. It means they are not linearly correlated but can be non-linearly correlated.
Figure 1 shows some examples of how the data looks with some of the values from Pearson’s Correlation.
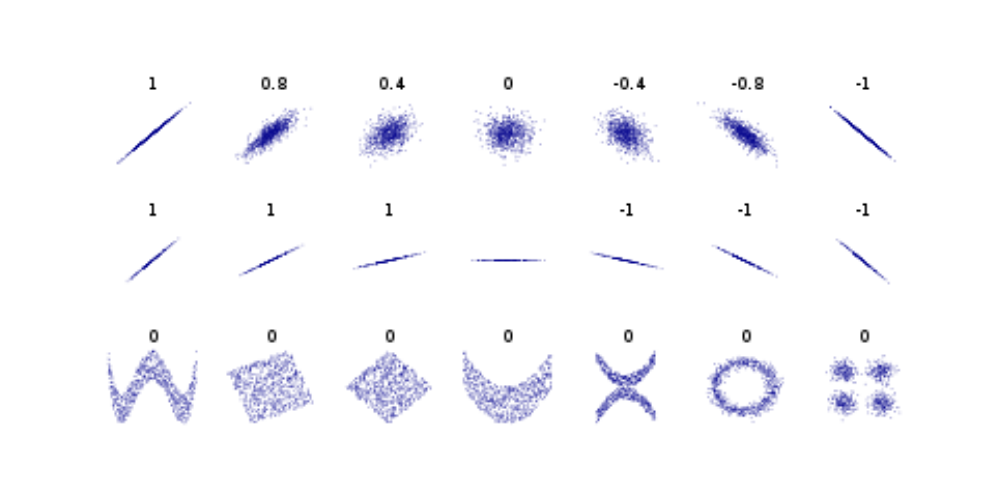
What Is Spearman Correlation?
Another measure is the Spearman Correlation, which is similar to the Pearson Correlation, but it considers the order of the data instead. It’s also used for quantitative data but can be used for ordinal qualitative variables since this technique uses ranks in its calculations. So you can assign ranks to ordinal attributes. The Spearman Correlation assesses the monotonic relationship between two continuous or ordinal variables. It is not sensitive to asymmetries in the distribution or the presence of outliers since we consider the order and not the values of the variables. There are other rank correlation coefficients besides Spearman, such as Kendall rank correlation. As we can see in figure 2, there is a comparison between Spearman and Pearson Correlation that shows a perfect correlation for Spearman, but not for Pearson. The reason is that the data is monotonic, not linear.

Other Techniques
The details of each technique go beyond this article’s scope, but keep in mind that it’s important to check the variable’s type first and then choose the proper method for it. If you pick two quantitative variables, you can choose between Pearson Correlation or Spearman Correlation. If you choose two qualitative variables and they are ordinal, you can use any rank correlation technique. If they are nominal, you can use Chi-Square, Cramers V, or Goodman Kruskal’s lambda. If you are using one quantitative and one qualitative variable, then Point-biserial correlation or the Logistic Regression. Of course, these recommendations are just high-level ideas. The choice will depend on the distributions of the data, the size of the dataset, and the objective of the analysis.
How to Use Graphical/Tabular Analysis
Another way to analyze the data is with graphs and tables. It’s important to note that the variable’s type will determine the best chart to use. The following are some of the most frequent graphs used for quantitative and qualitative attributes to give you an idea.
Most frequent visual analysis for qualitative variables
Frequency Tables: Frequency tables summarize the data information into absolute or relative frequencies of each value (category). You can use them for qualitative and discrete data.
Bar Charts: You can also use bar charts to represent this frequency table in graphical form. This kind of graph is usually used to show the individual values of each column (feature/attributes) and make some comparison among all columns, identifying the ones with highest and lowest values.
Pareto Plots: Another useful chart for this type of variable is the Pareto plot, which helps identify the top issues that account for most of the problems based on the Pareto principle. This graph is based on a bar chart and line chart, where the latter represents the cumulative frequency (see figure 3).

Pie Charts: Another typical graph used for this type of variable is the Pie chart. However, according to Storytelling with Data author Cole Knaflic, you should avoid using pie charts because they can be hard to read and difficult to tell which slice is bigger (and by how much) when they are very similar in size. As an alternative to using pie charts, you can use horizontal bar charts with ordered data. However, to see the relationship of one part to the whole, the pie chart is a better choice.
Contingency Tables: One way to visualize the relationship of two qualitative data is through the contingency table, which displays the frequency distribution of the given attributes in a matrix.
Most Frequent Visual Analysis for Quantitative Variables
Histograms: Histograms are graphical representations used to display the distribution of continuous data. The graph shows the position of the mean, median, dispersion, number of peaks, and more (see figure 4) and it’s useful to visualize the Univariate analysis we performed previously.

Line Plots: This chart is based on quantitative data and is often used to represent the data over a period of time. For example, if we want to understand the number of people affected by the Covid over time, the y-axis would represent the quantitative data about the number of people affected, and the x-axis would represent the date over a time period.
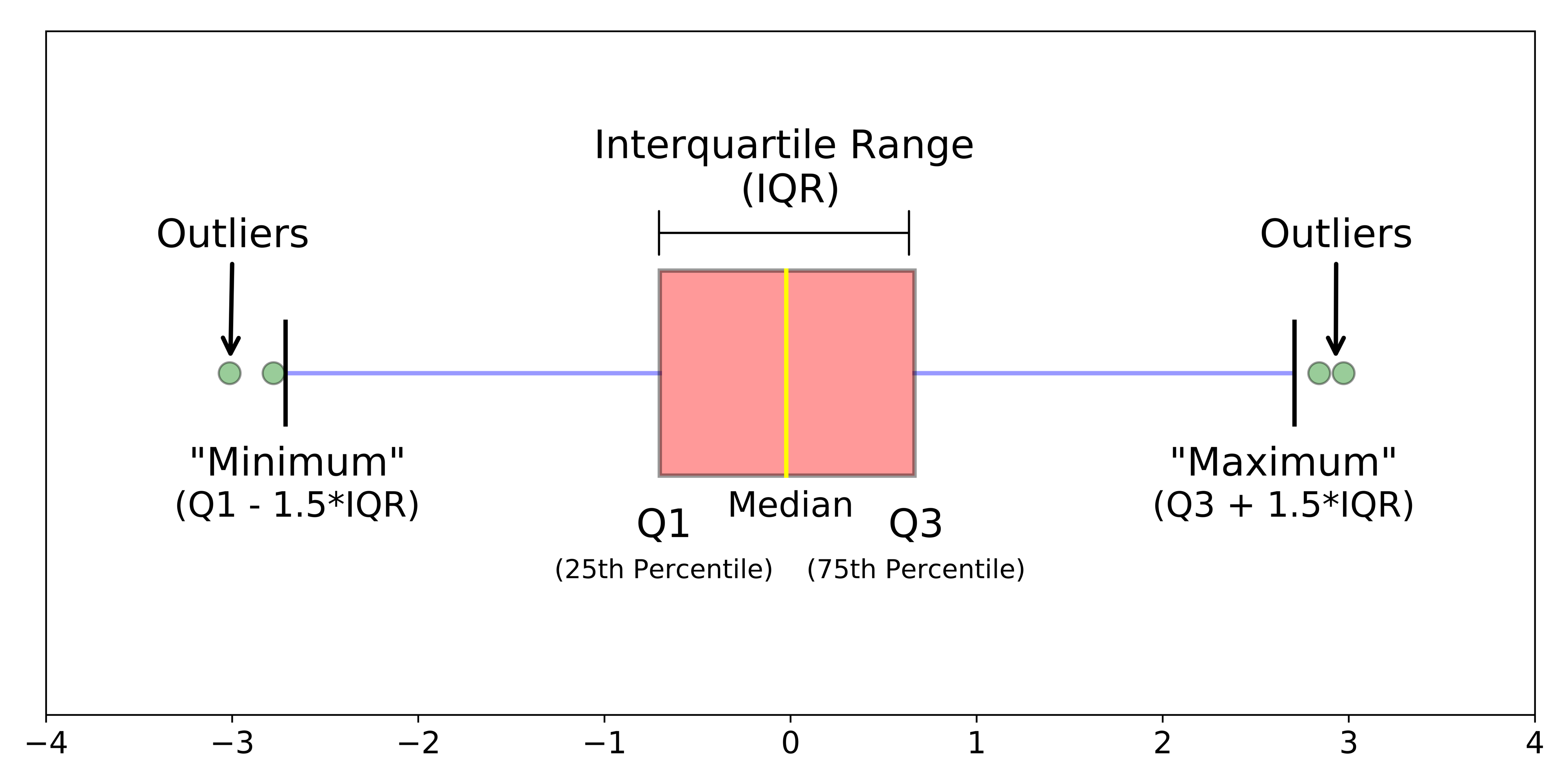
Box Plots: Another powerful graph is the box plot, and it’s usually challenging to understand when it’s the first time you see it. However, after understanding the nuances of that chart (see figure 6), you will easily observe the median, interquartile range, dispersion of the data, asymmetry, and the discrepant values, also known as outliers. But before understanding the outliers concept, let’s see some ways to represent the multivariate analysis.
Scatterplots: Scatterplots are one of the most used graphs to compare the correlation of two quantitative variables. The y-axis represents one variable and the x-axis another.
Heat Maps: The heat map is another data visualization that is widely used, where a color represents the individual values of the matrix. Usually, intense colors represent higher values. There are many ways to use heat maps. For instance, you can apply the Pearson Correlation of all quantitative attributes from a dataset (see figure 7) to understand what variables have a high correlation. After, you can confirm with the scatterplot.

Checking the Existence of Outliers in the Variables
The last critical analysis to explore is the detection of outliers. Outliers are examples within the range of possible values that fall outside most instances in the dataset. There are three kinds of outliers: global, contextual, and collective.
- Global: Global outliers are data points that occur far outside of most of the data. The simplest way to identify them is in the box plot – dots that appear in the chart are considered anomalous data.
- Contextual: Data points that are considered contextual outliers are those that are not individually outliers (like global outliers) but when observed in certain contexts are. For example, let’s say that babies born between 38 and 42 weeks are of normal size if they range from 5.5 to 8.8 pounds. If a baby is born at 37 weeks and is 8.6 Lbs, then we have a contextual outlier. Looking only at the size, it’s not an outlier, but when adding in the context of weeks, the baby deviates from the majority of babies.
- Collective: Collective outliers are sets of data that deviate from the rest of the data set when looked at collectively, but are not considered global or contextual outliers. For example, if we observe the birth of male and female babies each month, and only male babies are born in a specific month, then it’s a collective outlier.
There are many ways to automate the process of detecting outliers, using either statistical data science methods with standard deviations, interquartile range, normal distribution, or by some machine learning methods, like clustering. Even though these techniques help automate this process, I encourage you to do the manual analysis before automating it in order to guarantee that the data and the method you plan to use will remove the outliers properly. We looked at the different ways to find outliers in the data, which plays an essential role in the process. As we saw previously, some measures are highly affected by outliers. Some models are very sensitive to outliers, while others are not. So depending on the model in use, it’s necessary to treat the data correctly.
Other Tools and Techniques
Using Automated Processes to Do a Pre-Exploratory Data Analysis
As we’ve discussed, there are many techniques and ways to do Exploratory Data Analysis to understand how the data is structured. The EDA is a manual process that helps you fully understand the data, its distribution, and the presence or absence of outliers. However, some packages automate the EDA for you. For those who know Python, the two most common libraries are pandas-profiling and sweetviz. These tools provide helpful information about the data and cover some of the topics discussed in this article. Nevertheless, I strongly recommend only using tools like these as an initial analysis to get an overview of the data before applying what is covered here manually.
Wrap Up
To summarize, the Exploratory Data Analysis phase helps you gain more knowledge about the domain and prevent potential issues from occurring. Once the analysis is complete, you will find that some data may be fixed or ignored. The model will not be built using all variables, either because some variables are irrelevant or because one variable has a high correlation with another. Additionally, you will know in advance the distribution of your data and the existence or non-existence of outliers, which can significantly impact the model you choose. With that, you will understand the data’s patterns and trends and gain valuable insights.
Also, it’s essential to highlight all findings you noticed from the Exploratory Data Analysis, the concerns and ideas for the given project that you got from the analysis, and all the work you will need to do in the preprocessing pipeline to train your model with adequate data. For those who want to get deeper into this topic, here are some book suggestions:
As a final note, keep in mind that this is a cyclic process that a data scientist should apply more than once in most cases. It’s important to frequently do this analysis with the data, even if you’ve done it in the past, because the data may change in the future, and new patterns, trends, and distributions can arise.
Are you looking for help with your next software project?
You’ve come to the right place. Our technical recruitment team has been carefully handpicked. Contact us and we’ll have your team up and running in no time.